-
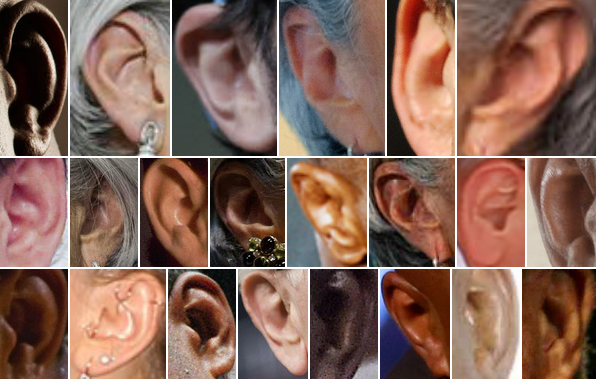
Annotated Web Ears (AWE) Dataset
This dataset was collected using images from the web to ensure large variability based from unconstrained environments. 100 subjects were selected among some of the most famous people, across different ethnicities, genders and ages. For each subject 10 images were selected and images tightly cropped. each image is also annotated and stored in JSON files with the annotations listed below. This dataset was later also incorporated into the UERC datasets.
Properties of the dataset:- 1,000 images
- 100 subjects
- 10 images/subject
- Gender: female (f), male (m)
- Ethnicity: caucasian (1), asian (2), south asian (3), black (4), middle eastern (5), hispanic (6), other
- Presence of Accessories: none (0), mild (1), significant (2)
- Occlusions: none (0), mild (1), severe (2)
- Head Side: left (l), right (r)
- Head Pitch: none (0), mild (1), severe (2)
- Head Roll: none (0), mild (1), severe (2)
- Head Yaw: none - profile (0), mild (1), severe (2)
Fill in and sign this form and send it to ziga.emersic@fri.uni-lj.si with the subject "AWE Request: AWE Dataset".
- Ear Recognition: More Than a Survey
- Covariate analysis of descriptor-based ear recognition techniques
- Training Convolutional Neural Networks with Limited Training Data for Ear Recognition in the Wild
- Towards Accessories-Aware Ear Recognition
- Assessment of predictive clustering trees on 2D-image-based ear recognition
- Influence of Alignment on Ear Recognition: Case Study on AWE Dataset
@article{emersic2017ear, title={Ear recognition: More than a survey}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and {\v{S}}truc, Vitomir and Peer, Peter}, journal={Neurocomputing}, volume={255}, pages={26--39}, year={2017}, publisher={Elsevier} } @article{emersic2018convolutional, title={Convolutional encoder--decoder networks for pixel-wise ear detection and segmentation}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Gabriel, Luka L and {\v{S}}truc, Vitomir and Peer, Peter}, journal={IET Biometrics}, volume={7}, number={3}, pages={175--184}, year={2018}, publisher={IET} } @article{EarEvaluation2018, title={Evaluation and analysis of ear recognition models: performance, complexity and resource requirements}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Meden, Bla{\v{z}} and Peer, Peter and {\v{S}}truc, Vitomir}, journal={Neural computing and applications}, pages={1--16}, year={2018}, publisher={Springer} } -
KinEar Dataset
This dataset was collected using images from the web to ensure large variability based from unconstrained environments. 100 subjects were selected among some of the most famous people, across different ethnicities, genders and ages. For each subject 10 images were selected and images tightly cropped. each image is also annotated and stored in JSON files with the annotations listed below. This dataset was later also incorporated into the UERC datasets.
Properties of the dataset:- 1,477 images
- 76 subjects
- 37282 kin image pairs

Fill in and sign this form and send it to ziga.emersic@fri.uni-lj.si with the subject "AWE Request: KinEar Dataset".
@article{kinear2022, title={Kinship Verification from Ear Images: An Explorative Study with Deep Learning Models}, author={Dvor{\v{s}}ak, Grega and Diwedi, Ankita and {\v{S}}truc, Vitomir and Peer, Peter and Emer{\v{s}}i{\v{c}}, {\v{Z}}iga}, journal={International Workshop on Biometrics and Forensics}, year={2022}, publisher={IEEE} } -
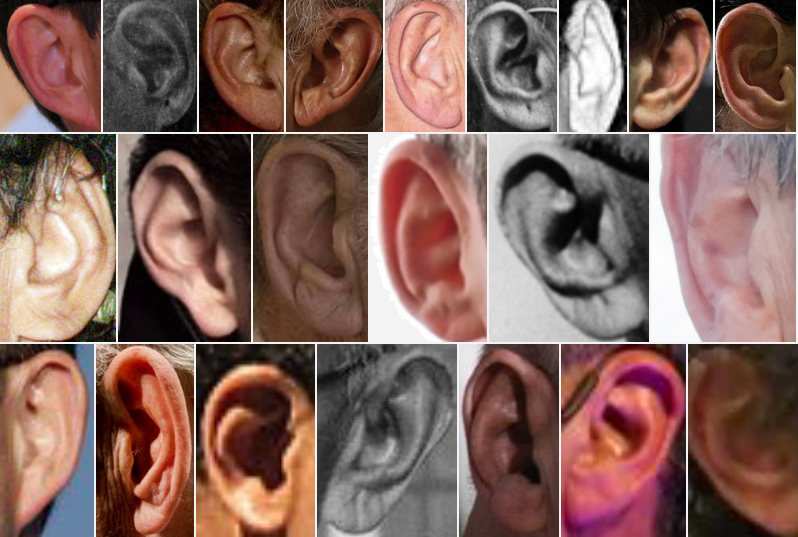
Unconstrained Ear Recognition Challenge (UERC) 2019 Dataset
This dataset is almost identical to UERC 2017, with only a few changed subjects. The dataset contains images from AWE, AWEx, CVL datasets and added 9,500 images that are smaller and served during the competition as impostors. Each image in the train part of the dataset is also annotated and stored in JSON files with the annotations listed below (same as the original AWE or the extended AWE).
Properties of the dataset:- 11,804 images (2,304 in the train part, 9,500 in the test part)
- 3,704 subjects (166 in the train part, 3,540 in the test part)
- 10 images/subject
- Gender: female (f), male (m)
- Ethnicity: caucasian (1), asian (2), south asian (3), black (4), middle eastern (5), hispanic (6), other
- Presence of Accessories: none (0), mild (1), significant (2)
- Occlusions: none (0), mild (1), severe (2)
- Head Side: left (l), right (r)
- Head Pitch: none (0), mild (1), severe (2)
- Head Roll: none (0), mild (1), severe (2)
- Head Yaw: none - profile (0), mild (1), severe (2)
Fill in and sign this form and send it to ziga.emersic@fri.uni-lj.si with the subject "UERC Request: The Dataset".
@article{emersic2017ear, title={Ear recognition: More than a survey}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and {\v{S}}truc, Vitomir and Peer, Peter}, journal={Neurocomputing}, volume={255}, pages={26--39}, year={2017}, publisher={Elsevier} } @article{emersic2018convolutional, title={Convolutional encoder--decoder networks for pixel-wise ear detection and segmentation}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Gabriel, Luka L and {\v{S}}truc, Vitomir and Peer, Peter}, journal={IET Biometrics}, volume={7}, number={3}, pages={175--184}, year={2018}, publisher={IET} } @article{EarEvaluation2018, title={Evaluation and analysis of ear recognition models: performance, complexity and resource requirements}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Meden, Bla{\v{z}} and Peer, Peter and {\v{S}}truc, Vitomir}, journal={Neural computing and applications}, pages={1--16}, year={2018}, publisher={Springer} } @Inbook{DeepEar2019, author="Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Kri{\v{z}}aj, Janez and {\v{S}}truc, Vitomir and Peer, Peter", editor="Hassaballah, Mahmoud and Hosny, Khalid M.", title="Deep Ear Recognition Pipeline", bookTitle="Recent Advances in Computer Vision: Theories and Applications", year="2019", publisher="Springer International Publishing", address="Cham", pages="333--362", abstract="Ear recognition has seen multiple improvements in recent years and still remains very active today. However, it has been approached from recognition and detection perspective separately. Furthermore, deep-learning-based approachesEmer{\v{s}}i{\v{c}}, {\v{Z}}iga that are popular in other domains have seen limited use in ear recognition and even more so in ear detection. Moreover, to obtain a usableKri{\v{z}}aj, Janez recognition system a unified pipeline{\v{S}}truc, Vitomir is needed. The input in such system should be plain images of subjects and thePeer, Peter output identities based only on ear biometrics. We conduct separate analysis through detection and identification experiments on the challenging dataset and, using the best approaches, present a novel, unified pipeline. The pipeline is based on convolutional neural networks (CNN) and presents, to the best of our knowledge, the first CNN-based ear recognition pipeline. The pipeline incorporates both, the detection of ears on arbitrary images of people, as well as recognition on these segmented ear regions. The experiments show that the presented system is a state-of-the-art system and, thus, a good foundation for future real-word ear recognition systems.", isbn="978-3-030-03000-1", doi="10.1007/978-3-030-03000-1_14", url="https://doi.org/10.1007/978-3-030-03000-1_14" } @inproceedings{UERC2017, title={The unconstrained ear recognition challenge}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and {\v{S}}tepec, Dejan and {\v{S}}truc, Vitomir and Peer, Peter and George, Anjith and Ahmad, Adii and Omar, Elshibani and Boult, Terranee E and Safdaii, Reza and Zhou, Yuxiang and others}, booktitle={2017 IEEE international joint conference on biometrics (IJCB)}, pages={715--724}, year={2017}, organization={IEEE} } @inproceedings{UERC2019, title={The Unconstrained Ear Recognition Challenge 2019}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}} and SV, A Kumar and Harish, BS and Gutfeter, W and Khiarak, JN and Pacut, A and Hansley, E and Segundo, M Pamplona and Sarkar, S and Park, HJ and others}, booktitle={2019 International Conference on Biometrics (ICB)}, pages={1--15}, year={2019}, organization={IEEE} } -
Unconstrained Ear Recognition Challenge (UERC) 2017 Dataset
This competition dataset contains images from AWE, AWEx, CVL datasets and added 9,500 images that are smaller and served during the competition as impostors. Each image in the train part of the dataset is also annotated and stored in JSON files with the annotations listed below (same as the original AWE or the extended AWE).
Properties of the dataset:- 11,804 images (2,304 in the train part, 9,500 in the test part)
- 3,704 subjects (166 in the train part, 3,540 in the test part)
- 10 images/subject
- Gender: female (f), male (m)
- Ethnicity: caucasian (1), asian (2), south asian (3), black (4), middle eastern (5), hispanic (6), other
- Presence of Accessories: none (0), mild (1), significant (2)
- Occlusions: none (0), mild (1), severe (2)
- Head Side: left (l), right (r)
- Head Pitch: none (0), mild (1), severe (2)
- Head Roll: none (0), mild (1), severe (2)
- Head Yaw: none - profile (0), mild (1), severe (2)
Fill in and sign this form and send it to ziga.emersic@fri.uni-lj.si with the subject "UERC Request: The Dataset".
@article{emersic2017ear, title={Ear recognition: More than a survey}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and {\v{S}}truc, Vitomir and Peer, Peter}, journal={Neurocomputing}, volume={255}, pages={26--39}, year={2017}, publisher={Elsevier} } @article{emersic2018convolutional, title={Convolutional encoder--decoder networks for pixel-wise ear detection and segmentation}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Gabriel, Luka L and {\v{S}}truc, Vitomir and Peer, Peter}, journal={IET Biometrics}, volume={7}, number={3}, pages={175--184}, year={2018}, publisher={IET} } @article{EarEvaluation2018, title={Evaluation and analysis of ear recognition models: performance, complexity and resource requirements}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Meden, Bla{\v{z}} and Peer, Peter and {\v{S}}truc, Vitomir}, journal={Neural computing and applications}, pages={1--16}, year={2018}, publisher={Springer} } @Inbook{DeepEar2019, author="Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Kri{\v{z}}aj, Janez and {\v{S}}truc, Vitomir and Peer, Peter", editor="Hassaballah, Mahmoud and Hosny, Khalid M.", title="Deep Ear Recognition Pipeline", bookTitle="Recent Advances in Computer Vision: Theories and Applications", year="2019", publisher="Springer International Publishing", address="Cham", pages="333--362", abstract="Ear recognition has seen multiple improvements in recent years and still remains very active today. However, it has been approached from recognition and detection perspective separately. Furthermore, deep-learning-based approachesEmer{\v{s}}i{\v{c}}, {\v{Z}}iga that are popular in other domains have seen limited use in ear recognition and even more so in ear detection. Moreover, to obtain a usableKri{\v{z}}aj, Janez recognition system a unified pipeline{\v{S}}truc, Vitomir is needed. The input in such system should be plain images of subjects and thePeer, Peter output identities based only on ear biometrics. We conduct separate analysis through detection and identification experiments on the challenging dataset and, using the best approaches, present a novel, unified pipeline. The pipeline is based on convolutional neural networks (CNN) and presents, to the best of our knowledge, the first CNN-based ear recognition pipeline. The pipeline incorporates both, the detection of ears on arbitrary images of people, as well as recognition on these segmented ear regions. The experiments show that the presented system is a state-of-the-art system and, thus, a good foundation for future real-word ear recognition systems.", isbn="978-3-030-03000-1", doi="10.1007/978-3-030-03000-1_14", url="https://doi.org/10.1007/978-3-030-03000-1_14" } @inproceedings{UERC2017, title={The unconstrained ear recognition challenge}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and {\v{S}}tepec, Dejan and {\v{S}}truc, Vitomir and Peer, Peter and George, Anjith and Ahmad, Adii and Omar, Elshibani and Boult, Terranee E and Safdaii, Reza and Zhou, Yuxiang and others}, booktitle={2017 IEEE international joint conference on biometrics (IJCB)}, pages={715--724}, year={2017}, organization={IEEE} } @inproceedings{UERC2019, title={The Unconstrained Ear Recognition Challenge 2019}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}} and SV, A Kumar and Harish, BS and Gutfeter, W and Khiarak, JN and Pacut, A and Hansley, E and Segundo, M Pamplona and Sarkar, S and Park, HJ and others}, booktitle={2019 International Conference on Biometrics (ICB)}, pages={1--15}, year={2019}, organization={IEEE} } -
Annotated Web Ears - Extended (AWEx) Dataset
This dataset was collected the same way as the original AWE dataset, but with additional subjects. Using images from the web to ensure large variability based from unconstrained environments. 230 subjects were selected among some of the most famous people, across different ethnicities, genders and ages. For each subject 10 images were selected and images tightly cropped. each image is also annotated and stored in JSON files with the annotations listed below. The dataset also contains the original AWE images.
Properties of the dataset:- 4,104 images (1,000 from AWE, 804 from the CVL dataset, 2300 new images)
- 346 subjects (100 from AWE, 16 from CVL, 230 new images)
- for 330 subjects 10 images/subject, for 16 subjects from CVL dataset 19 to 94 images/subject
- Gender: female (f), male (m)
- Ethnicity: caucasian (1), asian (2), south asian (3), black (4), middle eastern (5), hispanic (6), other
- Presence of Accessories: none (0), mild (1), significant (2)
- Occlusions: none (0), mild (1), severe (2)
- Head Side: left (l), right (r)
- Head Pitch: none (0), mild (1), severe (2)
- Head Roll: none (0), mild (1), severe (2)
- Head Yaw: none - profile (0), mild (1), severe (2)
Fill in and sign this form and send it to ziga.emersic@fri.uni-lj.si with the subject "AWE Request: AWEx Dataset".
@article{emersic2017ear, title={Ear recognition: More than a survey}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and {\v{S}}truc, Vitomir and Peer, Peter}, journal={Neurocomputing}, volume={255}, pages={26--39}, year={2017}, publisher={Elsevier} } @article{emersic2018convolutional, title={Convolutional encoder--decoder networks for pixel-wise ear detection and segmentation}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Gabriel, Luka L and {\v{S}}truc, Vitomir and Peer, Peter}, journal={IET Biometrics}, volume={7}, number={3}, pages={175--184}, year={2018}, publisher={IET} } @article{EarEvaluation2018, title={Evaluation and analysis of ear recognition models: performance, complexity and resource requirements}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Meden, Bla{\v{z}} and Peer, Peter and {\v{S}}truc, Vitomir}, journal={Neural computing and applications}, pages={1--16}, year={2018}, publisher={Springer} } -
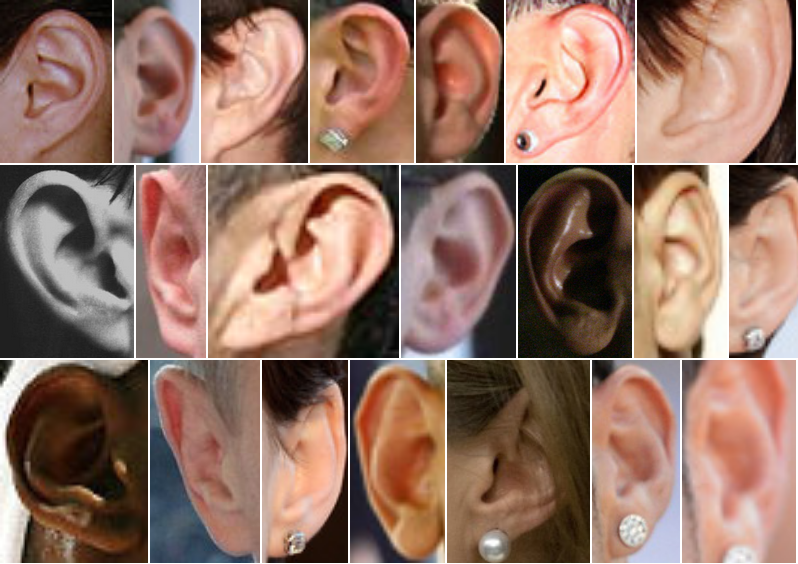
Additional (CVL Ear) Dataset
This dataset was collected the same way as the original AWE dataset, but with different subjects and significantly larger number of images per subjects (variable) and only 10 subjects. This dataset was later incorporated into the UERC datasets. This dataset was collected using images from the web to ensure large variability based from unconstrained environments. 10 subjects were selected among some of the most famous people, across different ethnicities, genders and ages. All images are tightly cropped. each image is also annotated and stored in JSON files with the annotations listed below. These annotations differ to AWE and UERC datasets in that they also contain locations of tragus points.
Properties of the dataset:- 804 images
- 16 subjects
- from 19 to 94 images images/subject
- Gender: female (f), male (m)
- Ethnicity: caucasian (1), asian (2), south asian (3), black (4), middle eastern (5), hispanic (6), other
- Presence of Accessories: none (0), mild (1), significant (2)
- Occlusions: none (0), mild (1), severe (2)
- Head Side: left (l), right (r)
- Head Pitch: none (0), mild (1), severe (2)
- Head Roll: none (0), mild (1), severe (2)
- Head Yaw: none - profile (0), mild (1), severe (2)
- Tragus Position X: value in pixels from top left
- Tragus Position Y: value in pixels from top left
Fill in and sign this form and send it to ziga.emersic@fri.uni-lj.si with the subject "AWE Request: CVL Ear Dataset".
@article{emersic2017ear, title={Ear recognition: More than a survey}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and {\v{S}}truc, Vitomir and Peer, Peter}, journal={Neurocomputing}, volume={255}, pages={26--39}, year={2017}, publisher={Elsevier} } @article{emersic2018convolutional, title={Convolutional encoder--decoder networks for pixel-wise ear detection and segmentation}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Gabriel, Luka L and {\v{S}}truc, Vitomir and Peer, Peter}, journal={IET Biometrics}, volume={7}, number={3}, pages={175--184}, year={2018}, publisher={IET} } @article{EarEvaluation2018, title={Evaluation and analysis of ear recognition models: performance, complexity and resource requirements}, author={Emer{\v{s}}i{\v{c}}, {\v{Z}}iga and Meden, Bla{\v{z}} and Peer, Peter and {\v{S}}truc, Vitomir}, journal={Neural computing and applications}, pages={1--16}, year={2018}, publisher={Springer} }

